|
L. WIESSING AND R. HARTNOLL
European Monitoring Centre for Drugs and Drug Addiction, Lisbon, Portugal
C. ROSSI
Department of Mathematics, University of Rome “Tor Vergata”, Rome, Italy
Abstract
Introduction
Indicators
Dynamic models
Policy needs and problems using indicators and models
Conclusion
Annex
References
ABSTRACT
Indicators and models may help in studying and understanding the epidemiology of drug use at the international or macro level. Indicators of drug use are usually based on available routine data and give indirect information on prevalence and trends. They can be used to cover large geographical areas with a limited budget; however, they are usually limited in quality and scope. Modelling is based on mathematical theory and can be used to integrate data from different indicators and other sources. It can be used to estimate prevalence and incidence or to enhance the understanding of drug processes by simulating experiments that are difficult or impossible to perform in real life. A sufficient understanding of basic assumptions and limitations is crucial to the interpretation of modelling results. Depending on the availability and use of data, a whole continuum of modelling may exist, ranging from empirical analyses with a high applicability to real life, to theoretical hypothesis-generating exercises based on many assumptions. Compared with other areas, the epidemiology of drug use has so far made little use of modelling, partly because reliable data remain scarce; nevertheless, work on improving indicators and other data is in progress. In the field of drugs, some issues that continue to hamper the application of evidence-based policy-making are lack of a common understanding of priorities for study and intervention, lack of knowledge of the spread and progression of drug problems, and legal and moral discourses. Indicators and models, which are important, complementary tools for epidemiology at the macro level, may help to clarify such issues. Although the quality of data and thus the inferences to be drawn from them are often more limited than they are in in-depth empirical studies, macro-level assessments are necessary to guide national and international policy decisions.
One problem of drug epidemiology at the national and international, or macro, level is the sheer scale of activities. While data on drug use within a city or small region can be collected directly, usually no funding is available for studies covering large areas or a number of countries. Setting up such a study is not straight forward, because of differences between countries and regions and the many stakeholders involved. Data available at the macro level are often aggregated rather than describing individual cases; they are based on routine sources, with their limitations of analysis and interpretation. The question that arises is whether valid inferences can still be made at the macro level (and, if so, how). The present article aims to introduce briefly indicators and modelling, two different but complementary tools for use in policy-making at the macro level, and to point to some still unresolved problems in the field of drugs that interfere with such evidence-based approaches.
Epidemiologists describe the spread of disease in a population in order to provide evidence for public health interventions and policies. Basic epidemiological measures are prevalence, referring to all existing cases at a certain moment in time, and incidence, referring to all newly occurring cases in a certain time period. In order to understand causal factors that lead to disease, a risk factor analysis is usually performed by comparing individual cases with non-cases. In drug epidemiology, it is usually difficult to determine prevalence and incidence owing to the hidden nature of drug use. Normal sources of data such as medical services may be very incomplete, while standard tools such as household surveys may give biased response owing to social stigma and the low rate of social integration of heavy drug users. Added to those problems is the difficulty of collecting data of comparable quality from a large number of sources and countries when working at the macro level. Additional methods are necessary to estimate prevalence, incidence and trends in drug use over time.
In domains such as public health and economy, the concept of indicators has been developed for data collection on a large scale and for phenomena that are difficult to measure. Rather than aiming at exact prevalence and incidence figures, indicators are based on available routine data on disease, risk factors or consequences and may provide indirect information on the exact magnitude of and trends in the disease. Public health indicators rely on data sources such as mortality registers, population censuses, routine health-service records, epidemiological surveillance data, sample surveys or disease registers. The idea is to select variables from such sources that fulfil certain quality requirements (validity, reliability), in order to measure health and changes in health [1].
Work on indicators in the field of drug use began in London in the early 1970s. It spread across European cities via the Pompidou Group of the Council of Europe, continued to be developed in countries across Europe by the European Monitoring Centre for Drugs and Drug Addiction (EMCDDA) and is currently being implemented at the global level by the United Nations International Drug Control Programme [2-4]. Available data on drug use are limited and the choice of indicators has relied on a pragmatic approach. Currently, five so-called key indicators are being implemented by EMCDDA in the European Union: (a) general population and school surveys; (b) estimates of “problem” drug use; (c) data from drug treatment services; (d) drug-related deaths and mortality; and (e) drug-related infections (such as the human immunodeficiency virus (HIV) and hepatitis B and C) [4]. Standards have been developed and current work is focused on collecting data and overcoming practical problems in data quality and comparability. Other indicators are still at an early stage of development, such as those related to social problems and crime, hospital and emergency room data and data from popular meeting places of young people, including discos and nightclubs.
Interpreting data based on drug indicators is not always straightforward. It is sometimes assumed that the combined information of a set of indirect indicators reflects trends in the prevalence of problematic drug use; however, indicator data may show fluctuations unrelated to prevalence due to, for example, changes in heroin supply or decreases in risk behaviour. Indicators such as drug-treatment data, drug-related mortality and drug-related infectious diseases are, therefore, also important for their own sake and for evaluating interventions directed at each of the specific sub-populations at risk, in addition to being important for following trends in problematic drug use.
Indicator data are often of limited quality owing to their wide-ranging coverage and routine nature; thus it is dangerous to rely solely on indicators. Most routine data are not suitable for providing rapid insight into changing trends in problematic drug use. For instance, the average latency time of 5-8 years between first heroin use and first demand for treatment implies that treatment indicators are not suitable for monitoring drug use in the non-treated population [5, 6]. To interpret trends at the national level, such as an increase in drug-related deaths, and in order for appropriate measures to be taken, indicators should be complemented and validated by smaller in-depth studies. Regularly repeated, small-scale studies are also important in giving insights into possible or changing causes, risk factors or confounding factors of the observed trends, as additional background information can usually be gathered from such studies. Routine indicators and one-off or repeated studies together may give a more complete picture of a phenomenon such as problematic drug use. Indicators provide lower-quality data but at low cost and with wide geographical coverage, while local studies provide high-quality data from a more limited and often high-risk area.
Dynamic modelling originated from biology and infectious disease epidemiology [7]. Many recent advances in research were made in the field of infectious diseases, especially on the acquired immunodeficiency syndrome (AIDS) [8]. Over the last 15 years, developments in modelling have closely paralleled the increasing knowledge in etiology and transmission of AIDS and other sexually transmitted diseases. During that period, modelling studies moved from straightforward extrapolations of available AIDS data to highly complex transmission models with large sets of parameters. Modelling and empirical research on AIDS have been mutually informative about important concepts. While characteristics of patients pointed to the existence of specific groups with increased risk, such as homo sexual men and injecting drug users, dynamic modelling clarified the potential role of such “core groups” (with high-risk behaviour or assortative “like-with-like” mixing patterns and consequent high levels of infection) for the overall transmission dynamics within a susceptible population [9]. While the natural history of HIV infection was becoming clearer from cohort studies, modelling offered a means of clarification and simplification (for example, by determining a number of discrete disease stages), thus providing a basis for policy decisions (for example, on treatment needs per disease stage) [10]. The effect of potentially important biological parameters that could not easily be studied empirically were often postulated from dynamic modelling work. For example, a simulation model could show that the high level of infectiousness during the first weeks of HIV infection could in some cases determine the occurrence of most new infections in the population, raising some questions about the effectiveness of HIV screening as a prevention tool under all circumstances [11, 12].
For drug epidemiology at the macro level, dynamic modelling can be a valuable complementary tool for following trends in indicators and other direct data analysis. In the more usual inductive or empirical method of data collection and interpretation, new insights follow from observation. Conversely, dynamic modelling may often be nearer a deductive approach, where new insights follow from theory. The use of the outcomes in real-life situations is sometimes limited and it can be difficult to validate the model assumptions with the data. However, the importance of most types of dynamic modelling lies in the generation of theory and hypotheses that may provide a framework for further research and policy decisions.
It is not easy to define dynamic or mathematical models.
In order to understand how they are used, it may be helpful to compare them
with the more familiar statistical models, used for empirical data analysis,
although even there the difference is not sharp (see figure I). Most models
consist of a set of mathematical equations (often in the form of a computer
program) that describe a process (such as the spread of drug use) in a simplified
manner and that can be used to understand the behaviour of that process.
A whole continuum of models exists, between the extremes of pure empirical
data analysis with statistical models and using mathematical or economic
theory in dynamic models. Statistical modelling techniques, such as different
types of regression analysis, including factor, cluster and path analysis,
often rely much more on data than, for example, many compartmental or system
dynamics models, which are more theoretical. Such dynamic models may rely
more heavily on sometimes unproven assumptions and may often be based on
“thin” data (data of which the quality is not certain), which makes their
validity more difficult to determine.
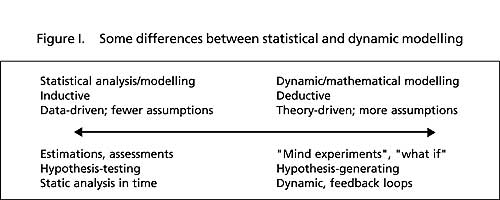
Note: This scheme does not fit all models. There are mathematical models that are data-driven and statistical models that are based on very little data. In addition, some statistical analysis (such as time series analysis and survival analysis) is not static in time and deterministic mathematical models can be used for estimations. Many models, however, appear to fit this scheme.
Both extremes of the modelling continuum are useful
in macro-level epidemiology, but in different ways. Rigorous analysis of
statistical data, such as regression analysis based on individual data records,
is usually not possible at the macro level, but statistical models can often
suggest useful answers when there are gaps in data of a certain type. That
can happen, for example, by imputing (that is, interpolating) prevalence
data from other moments in time or locations where more data are available,
or by using other data sources and if possible adjusting for potential biases,
making it possible to generate a result where originally no data were available
(although again special care must be taken in interpretation). There is a
clear need for such modelling in the field of drugs at the macro level, where
reliable data often do not exist.
At the other end of the continuum, dynamic or mathematical models can assist in understanding a phenomenon even if such models are almost entirely based on assumptions, with little or no data input. If the model is thought to describe a process in real life sufficiently well, the behaviour of such a process can be studied under different circumstances by varying parameter values and observing the variation in outcomes. Such a semi-experimental situation is sometimes called “what if” modelling, that is, the model explores what could happen under certain circumstances, if it can be assumed that the process under study has been captured by the model. Modelling, therefore, can provide a tool for simulating experiments that are not possible to perform in real life for practical or ethical reasons.
To interpret the results of modelling, it is important to understand the differences between the different types of model. Results can be seen either as scientific “facts” (statistical modelling), as theoretical hypotheses or even as something in-between, depending on the certainty of parameters and the validity of the basic model chosen. The limitations and assumptions of the model should always be stated clearly and presented together with the results. That is often difficult, even for specialists, and non-specialists may have no way of distinguishing valid results with important direct implications from academically interesting theory with little direct practical meaning.
To avoid such problems, it is important for modellers and other scientists to form multidisciplinary teams, although that is possible only if each team member has some understanding of the approaches used in the other disciplines and is prepared to acquire at least some knowledge of other fields. If such collaboration exists, the modeller may generate meaning from scarce data and the topic expert, such as the epidemiologist, can help to interpret the validity of the results against his or her knowledge of real-life situations and data quality issues.
If one concentrates only on dynamic or mathematical modelling (but most of the following also holds for statistical analysis/modelling), again different approaches are possible (see figure II). A relatively simple model that reflects the main elements and their relationships is often the starting point. A common criticism of such a model is that it fails to take into account a potentially important variable, which may subsequently be incorporated into the model, making the model more complex. The process may repeat itself until it results in highly complex models. Although the more complex models may resemble reality more closely than the simple ones do, it is often difficult to keep track of what exactly is happening. In practice, the complex models may not lead to better or more valid results. As was the case with regard to AIDS research, the process of increasing model complexity often directly reflects the state of existing knowledge in the field. However, while some modellers attempt to incorporate into their models as many parameters as possible in an attempt to increase the validity of their results, others prefer to work with simple models that can easily be understood. Simple models that succeed in giving new insights are often more influential than complex ones [13].

Sensitivity analysis is an important element, in particular
in the case of more complex models. In sensitivity analysis, the relative
influence of the different parameters on the modelling results is assessed.
Different, often extreme, values are taken for those parameters. It may be
found that the results are not sensitive to some of the parameters but very
sensitive to others, making it necessary for those parameters to be especially
reliable. In addition, the results of a complex modelling study can be analysed
by applying statistical sampling techniques to the modelling results, as
shown in a study of the spread of HIV in New York [14]
Another important question during the interpretation of modelling results is their intended use. Depending on the application of modelling results, one should be more or less conservative. A set of outcomes can be valid for publication in a reputable mathematical journal, where the emphasis is on methodological and theoretical advances, while the same outcomes may not be considered sufficiently rigorous to be published in a reputable applied journal (for example, one on public health), that focuses on the external validity of results and their practical consequences. Nevertheless, even for applied use, the question is sometimes whether it is better to have less valid information than no information at all, which may lead to results being accepted for policy decisions that are less valid than would be desirable from a strictly scientific point of view.
An example of the latter situation in drug epidemiology is prevalence estimation. Although sophisticated statistical models exist for prevalence estimation of problematic drug use at the local level, such as multi-sample capture-recapture models with loglinear regression parameter estimation [15], results may often not be clear owing to problems in data quality: they often have wide confidence intervals, which may still substantially underestimate uncertainty. At the macro level, such methods can often not easily be used because of geographical heterogeneity and the limited availability of national data. Simple multipliers may be used instead, while in some cases the uncertainty about data quality may make calculating confidence intervals meaningless [16]. At best, these methods give a qualitative indication of a range for plausibility of prevalence [17]. Nevertheless, it is important to have prevalence estimates at the local and national levels that form a basis for a large variety of policy choices. In general, low-quality estimates are accepted as the best approximations currently available. Other examples of accepting uncertain modelling results can be found in forecasts of future developments and in scenario analyses, which by definition are unreliable and may eventually prove to be wrong, but are of such importance to policy makers that they are widely used.
Epidemiology is an applied or problem-driven science in which emphasis is placed on the relevance of new knowledge to policy. It may therefore be useful to discuss briefly the possible needs of policy makers. This is especially important at the macro level, where the relevance of policy for individual drug users may be much less obvious than, for example, at the level of treatment or outreach services.
The needs of a policy maker may seem clear in general terms: it is necessary to describe and understand a problem and follow trends, to design appropriate interventions and to evaluate the results of interventions. In the case of drug use and its consequences, both indicators and models may contribute to a description and understanding of the problem, while indicators are specifically suited to following trends. Models may help in designing and choosing interventions, for example, by assessing the cost-effectiveness of alternative options, although the basic knowledge about what works (that is, the efficacy of different options) needs to be assessed in carefully designed empirical studies.
The reality, however, is less harmoniously arrived at than the above would suggest. At a global level, there is little consensus among scientists, service providers and policy makers about the most effective and relevant interventions. Opinions range from a “war on drugs” at one extreme to complete legalization at the other. The question that arises is what makes the field of drugs seem so much more complex than it appears to be in the first instance. In part, the answer may be of a purely scientific and methodological nature; however, it may also lie in part in the interplay between science and policy. Furthermore, some of the more methodological problems may be a consequence of working at a high level of aggregation.
Scientific or methodological problems, especially at the macro level, may include the lack of a clear case definition of what constitutes a drug user, the lack of knowledge of basic mechanisms for the spread of drug use and the lack of knowledge regarding progression into drug problems. These three areas are discussed below.
Firstly, using indicators at the macro level, it is often not possible to use a clear case definition of addiction or drug dependence, such as the fourth edition of the Diagnostic and Statistical Manual of Mental Disorders [18], or to use standard disease codes, such as the codes of the International Classification of Diseases, because of the quality and limitations of routine data. Indicators such as survey data may give data of high quality on lighter forms of drug use, but are expensive and usually not as reliable for heavier patterns of drug use, which cause most drug problems. Modelling techniques for prevalence estimation of problem drug use, such as capture-recapture, often rely on non-specialized data sources that give little detailed information on drug use (police data, hospital data, etc.) and make clear-cut case definitions inappropriate. In such cases, a pragmatic solution may be to define problem drug users as drug users who are in contact or in need of contact with health or social services.a In most countries in Europe, such a definition is usually limited to frequent heroin or amphetamine users; however, it is difficult to obtain more detail on the prevalence and patterns of problematic drug use, such as breakdowns by type of drug, from those techniques and it is important that they are complemented by local studies, based on, for example, out-of-treatment recruitment of drug users.
Secondly, more knowledge is required about the basic mechanisms for the spread of drug use and problem drug use or addiction. There is little consensus among scientists on which risk factors are the most influential, from the wide range of social, psychosocial and biological factors identified in different studies [19]. Until that situation changes, effective interventions cannot be expected. Such a lack of common understanding about a basic mechanism for the epidemiology of drug use also makes it difficult for consensus to be reached on results from modelling studies, which is not the case in more established fields such as infectious disease epidemiology or economy. Although models of spread are often partly based on assumptions, they can help to clarify the underlying processes. For example, there is evidence that drug use spreads like an infectious disease, that is, the rate of new cases depends on the number of existing cases and the number of those that are susceptible [20, 21]. Using the analogy with infectious diseases enables a large body of existing research to be used for the study of the spread of drug use. However, unlike the case of infectious diseases, the role of supply factors (including price of drugs and availability) is not well understood nor are the intentional marketing activities of drug dealers. In addition, “infectiousness” (that is, the probability of “infecting” another person) may not be as constant as in a biological context and may depend on a range of unknown social factors. For example, the spread of drug use may be influenced by the mass media, through developments in the music and fashion industries. Such factors may have contributed to the recent spread of Ecstasy (methylenedioxymethamphetamine (MDMA)) and other new synthetic drugs.
Thirdly, more work is needed to clarify the “natural history” or typical course of progression to problematic drug use. It may be less important to study what leads young people to experiment with illegal drugs, as that mechanism does not seem to differ from what leads people to experiment with alcohol or tobacco at earlier ages [22, 23]. It is, however, crucial to understand why some young people progress into using heroin dependence, while by far most never go beyond experimenting with cannabis. This may be due simply to social factors such as “meeting the wrong friends”. It may also be that some people are genetically prone to addiction or have other predisposing factors and that those who continue using drugs need to do so to ease negative moods or to “self-medicate” mental problems [24]. In the first case, again, a type of modelling similar to that for infectious diseases could be useful in, for example, predicting progression to heroin dependence and estimating cost-effectiveness of interventions. Concepts from infectious disease epidemiology might be applied, such as “infecteds”, “susceptibles”, “basic reproductive rate”b and “herd immunity”c . Key issues would be to distinguish “susceptibles” from “immunes” or to find a type of “vaccination” that could turn “susceptibles” into “immunes”. Prevention measures to be considered might then resemble those used in the infectious diseases field. In the second case, the epidemiology of illegal drug use might resemble more closely that of chronic diseases. The models would focus on demographic or social developments that would lead to higher or lower prevalence and incidence of the predisposing genetic or mental-health factors in the general population. It would then be important to identify those with a genetic or mental risk profile at an early stage and to find ways to protect such individuals from addiction to a substance or to a behaviour (such as gambling) later in life. In fact it is probable that a mix of both types of approaches should be used, that is, experimentation with drugs might follow infectious diseases patterns, while continued heavier use (dependence) may be more related to chronic diseases mechanisms.
In addition to the examples of scientific and methodological problems described above, other problems in the study of drug use exist, illustrating the intersection of science and policy. Possibly the clearest example is the illegal status of drug use, which may affect several problems in the field, both for scientists and policy makers. There are few epidemiological areas in which the disease under study is viewed as an illegal activity. The legal and moral aspects may complicate public health work on drug problems in the ways described below.
Firstly, methodologically sound studies on interventions are difficult to set up, because of the illegal status of patients and because some of the potential interventions are illegal. Those factors complicate the collection of hard evidence on policy options; thus, the debate continues in a vicious circle. An example of a controversial intervention is controlled heroin provision [25, 26]. Even substitution treatment, an alternative intervention that is well accepted in the scientific field [27], cannot be provided everywhere. Patients treated in law enforcement settings such as prisons do not always have the possibility of a confidential doctor-patient relationship. In addition, patients may be moving in and out of treatment and prisons, thus continuously interrupting therapy, which makes positive effects difficult to sustain. Such factors also greatly increase the risk of adverse consequences, including HIV infection or overdose [28-31]. Moreover, the legal restrictions and stigma concerning drug use in most countries may lead to difficulties in obtaining reliable routine data or indicators on the problem [32]. Drug users tend to avoid registries as much as possible, and some doctors have been known to give a drug-related death a less stigmatized code on the death certificate in order to protect the relatives of the deceased. Legal restrictions may affect scientific work in a more general manner, through their influence on funding priorities or pressure on scientists to select results that are politically correct.
Secondly, legal and moral perspectives may lead to a lack of clarity about the case definition in policy debates. Illegal drug use is often discussed only in general and vague terms; however, it is clearly important to distinguish problem drug use from non-problem drug use or cannabis use from heroin. In many countries cannabis use (which is usually non-problematic) does not differ in legal terms from heroin use (which is often problematic), yet the consequences in terms of public health are vastly different. Many forms of drug use, even if illegal, do not lead to more problems for the individual or society than does moderate smoking or alcohol use [33, 34]. Problematic drug use, such as injecting or frequent use of heroin, crack and other hard drugs, incurs most costs to society in the form of infections, deaths, addiction and crime [4, 35]. The aim of a policy maker is to try to minimize the social costs of drug use by formulating and implementing appropriate policy adapted to such an aim. It is thus those forms of drug use which incur the largest social costs which should be targeted first by interventions. Drug policies that do not distinguish between different modes of drug use may not be efficient and may even be counter-productive. Differentiating between light and heavy forms of drug use in policy objectives, and using case definitions based on clear diagnostic rather than legal criteria, could contribute substantially to progress in the field of drugs.
Thirdly, the lack of clarity in the definition of the problem and the lack of possibilities to gather scientific evidence have resulted in a lack of common objectives to reduce drug problems. Whereas there is no question about whether HIV infection or cancer should be prevented or not, such a consensus does not exist with regard to drug use. It is important to reach evidence-based agreement on general objectives and on an optimal balance of intervention priorities to reach those objectives [36]. Some decision makers believe that reducing all drug use (if it is possible to do so by law enforcement) will in turn lead to less problematic use, while others think that it is not possible and that law enforcement actually increases problematic use, having little or no effect on the prevalence of non- problematic drug use [37]. Both approaches, however, imply completely different and often conflicting interventions: legal and preventive in one and oriented towards public health in the other. It has been found that changes in law enforcement usually have little effect on levels of problematic drug use [38, 39] and that countries with totally different policies may show similar prevalence [4]. For those reasons, it may be more useful to aim at preventing problematic drug use and its secondary consequences, such as overdose and HIV transmission [40, 41], than to attempt to eliminate or prevent all forms of drug use. Most policies regarding alcohol abuse also focus on preventing problematic alcohol use and its consequences than on attempting to eliminate alcohol consumption altogether.
Five key indicators are being implemented in the member States of the European Union while others are still being developed. Data collection has started only recently. The quality of data and comparability issues have not yet been resolved. Many models of drug use exist but consensus on the basic mechanisms for the spread and progression of problematic drug use is still lacking, while legal issues surrounding drug use significantly complicate data collection and monitoring of problematic drug use, as well as the development and evaluation of effective interventions.
It is essential to improve the quality of the monitoring of problematic drug use. While non-problematic drug use can be followed through general population and school surveys, prevalence estimation of problematic drug use is still in its infancy. Prevalence and incidence are fundamental measures aimed at understanding the spread of problematic drug use and evaluating the effects of policy interventions. While prevalence by subgroups can provide information on the exit rates from the population (for example, through treatment), detailed information on incidence is important for assessing entry rates and evaluating preventive measures.
At present, the quality of the data does not permit the precise measurement of prevalence and incidence in most countries, even though important methodological advances are being made. It is necessary to obtain a greater commitment to quality data collection for both statistical estimation modelling and developing dynamic models in order to investigate policy choices. Legal barriers (including data protection laws) have to be removed to facilitate scientific work on all potentially useful interventions and to improve data availability.
More multidisciplinary work is needed to clarify and describe the spread of problematic drug use in space and time. Economic models need to be developed to enable better estimates to be made of the costs to society of the various consequences of drug use and of the cost-effectiveness of policy options. There is a need to clarify the role of supply factors, as well as the ways in which those factors interact with demand research into drug markets and, in particular, with progression to problematic drug use. There is a more advanced understanding of the spread of drug-related infectious diseases; however, practical work is needed on HIV prevention (such as increasing the coverage of interventions), and the prevention of hepatitis C infection still needs to be enhanced by improving injecting drug users' understanding of the routes of transmission of those viruses. As effectiveness of interventions cannot be assessed easily at the macro level, monitoring of the disease should at least include monitoring of the coverage of the target population [42].
In conclusion, indicators and models constitute important and complementary tools for the epidemiology of drug use at the macro level. Although the quality of the data and the inferences drawn from them are often weaker than those in local or in-depth studies, macro-level assessments are indispensable for guiding policy decisions. The interpretation of results should be carefully undertaken at the macro level, despite the urgent need for policy decisions to be made. There are still many problems specific to the field of drugs that need to be solved before effective measures can be widely adopted.
European Network to Develop Policy Relevant Models
and Socio-Economic Analyses of Drug Use,
Consequences and Interventions
A European network was established in 1999 with the aim of stimulating the use of modelling in the field of drug use. It is funded by the European Commission (DG Research, Targeted Socio-Economic Research) and coordinated by the European Monitoring Centre for Drugs and Drug Addiction. Six working groups cover three broad areas: two working groups are active in the field of prevalence estimation (at the local level and the national level), two are investigating the dynamics of drug use (geographical spread, time trends and incidence) and two are studying the economic aspects of drug use (costs, cost-effectiveness and drug markets). About 40 European modellers and other experts are participating in these working groups. Several advances have been made in the two years that regular meetings have been held. In the area of prevalence estimation, new methods (such as the truncated Poisson method) have been studied that may provide prevalence estimates from fewer data sources than are necessary in classical capture-recapture and methods that may account for non-closed populations. At the national level, a multivariate method has been applied that may be more robust than using simple multipliers (the multivariate indicator method). A model of geographical spread has been developed and linked with a geo graphic information system application that can be used to visualize spread between cities and smaller towns, based on various parameters, including geographical data on the year of peak prevalence and population size. A method has been developed to estimate incidence (initiation rates) of problematic drug use from treatment data using a back-calculation model analogous to the one used for AIDS. That work has also resulted in estimates of the latency time between first heroin use and first treatment for opiate addiction, in different cities in Europe, which is important for understanding the natural history of progression to heroin use. Different methods have also been developed to estimate the social costs of problematic drug use, placing emphasis on estimating costs of drug-related infections (notably HIV and hepatitis B and C); drug markets and supply-side factors have also been studied. The collaboration of many experts during the project has led to the publishing of a substantial amount of scientific work on the epidemiology of drug use in Europe. (For further details and a list of publications, see the information on the Internet at http://www.emcdda.org/situation/methods_tools/modelling_network.shtml)
*The present article benefited from the European Network to Develop Policy-Relevant Models and Socio-Economic Analyses of Drug Use, Consequences and Interventions, funded by the European Union (DG Research, Targeted Socio-Economic Research project ERB 4141 PL 980030). An earlier version of the article has appeared in European Monitoring Centre for Drugs and Drug Addiction scientific monograph number 6: Modelling Drug Use: Methods to Quantify and Understand Hidden Processes (Lisbon, European Monitoring Centre for Drugs and Drug Addiction, 2001). The authors are grateful for the helpful comments of Alred Uhl.
aAlthough EMCDDA defines problem drug use as "injecting drug use (IDU) or long duration/ regular use of opiates, cocaine and/or amphetamines", the estimates are in practice calculated from data on users contacting services.
b"Basic reproductive rate": average number of new cases "infected" by each existing case.
c"Herd immunity": protective effect of a high density of immune persons on the non-immunes in the population.
|

